Lei Zhang
Chief Scientist
Computer Vision & Robotics
International Digital Economy Academy (IDEA)
Guangdong-HongKong-Macau Greater Bay Area
Shenzhen, China
Email: leizhang AT idea dot edu dot cn

Chief Scientist
Computer Vision & Robotics
International Digital Economy Academy (IDEA)
Guangdong-HongKong-Macau Greater Bay Area
Shenzhen, China
Email: leizhang AT idea dot edu dot cn
I am the Chief Scientist of Computer Vision and Robotics at International Digital Economy Academy (IDEA) and an Adjunct Professor of Hong Kong University of Science and Technology (Guangzhou). Prior to this, I was a Principal Researcher and Research Manager at Microsoft, where I have worked since 2001 in Microsoft Research Asia (MSRA) for 12 years and later joined Bing Multimedia, Microsoft Research (MSR, Redmond), and Microsoft Cloud & AI from 2013 to 2021. My research interests are in computer vision and machine learning. I am particularly intersted in generic visual recognition at large scale and was named as IEEE Fellow for my contributions in this area.
I have served as editorial board members for IEEE T-MM, T-CSVT, and Multimedia System Journal, as program co-chairs, area chairs, or committee members for many top conferences. I have published 150+ papers and hold 60+ US patents.
I received all my degrees (B.E., M.E., and Ph.D) in Computer Science from Tsinghua University.
Our team has made significant contributions to object detection, including DINO, detrex, Grounding DINO, Grounded SAM, T-Rex2, and Grounding DINO 1.5.
We are hiring both researchers and engineers working on computer vision and machine learning. Note that we don’t have a clear boundary between these two roles. Most of our high impact projects are the result of team work with both researchers and engineers. Therefore, we expect our researchers to have solid engineering skills and our engineers to have good knowledge on research algorithms.
We are also looking for research and engineering interns. In particular, we currently look for interns who have good experience on model architecture design, optimization, and compression, and are interested in deploying vision models to resource-constrained hardware devices.
I normally recruit one PhD student each year at SCUT and start to recruit 1-2 PhD students from 2024 at HKUST-GZ in the general area of computer vision, including object detection, segmentation, open-vocabulary recognition, multi-modality understanding, contention generation, etc.
If you are interested, please send me your resume with subject “Job application in IDEA” or “Intern application in IDEA” or “PhD application”. I won’t be able to reply each individual email. But if I find your experience a good fit to our team, I will get back.
For all positions, we value your core skills. If you’ve done any interesting research or made extensive contributions to any open-source project, highlight that in your resume and inquiry email!
Grounding DINO 1.5 Pro
Grounding DINO 1.5 Edge
Grounding DINO 1.5 improves Grounding DINO with two distinct models. The Pro model aims to push the boundary of open-set object detection, setting new records on zero-shot detection benchmarks: 54.3 AP on COCO, 55.7 AP on LVIS, and 30.2 AP on ODinW. The Edge model is optimized for speed, achieving 75.2 FPS on NVIDIA A100 and over 10 FPS on NVIDIA Orin NX while maintaining an excellent balance between efficiency and accuracy.
[ Paper | Blog | Playground ]
T-Rex2 uniquely combines text and visual prompts for open-set object detection. In particular, its visual prompt capability can unlock a wide range of scenarios without the need for task-specific tuning or extensive training datasets.
[ Paper | Blog | Playground ]
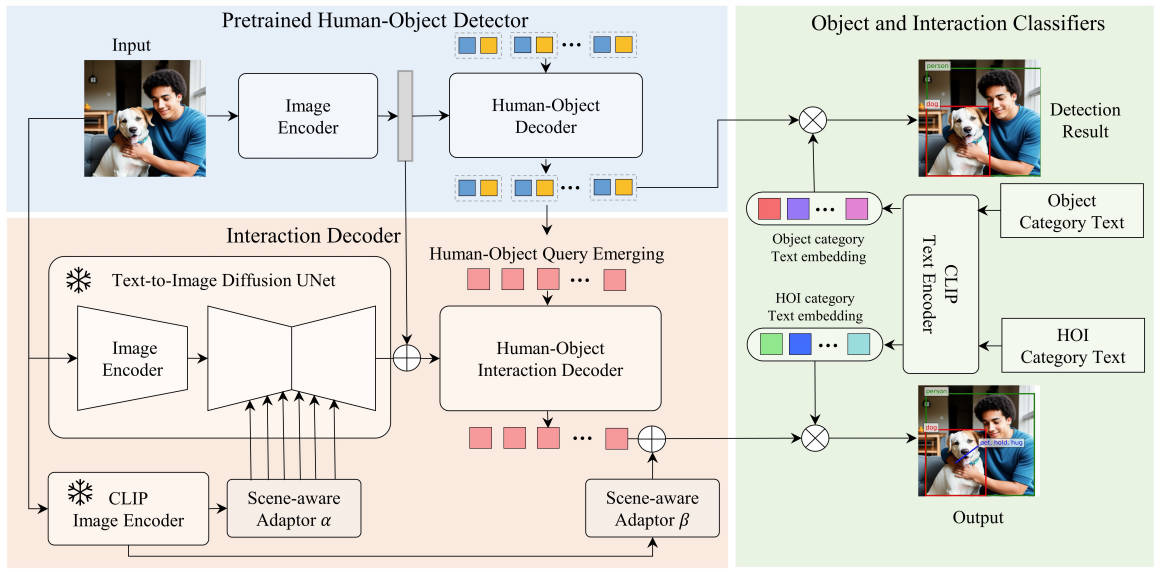
@inproceedings{yang2024openworld,
title = {Open-World Human-Object Interaction Detection via Multi-modal Prompts},
author = {Yang, Jie and Li, Bingliang and Zeng, Ailing and Zhang, Lei and Zhang, Ruimao},
booktitle = {Computer Vision and Pattern Recognition (CVPR)},
year = {2024}
}
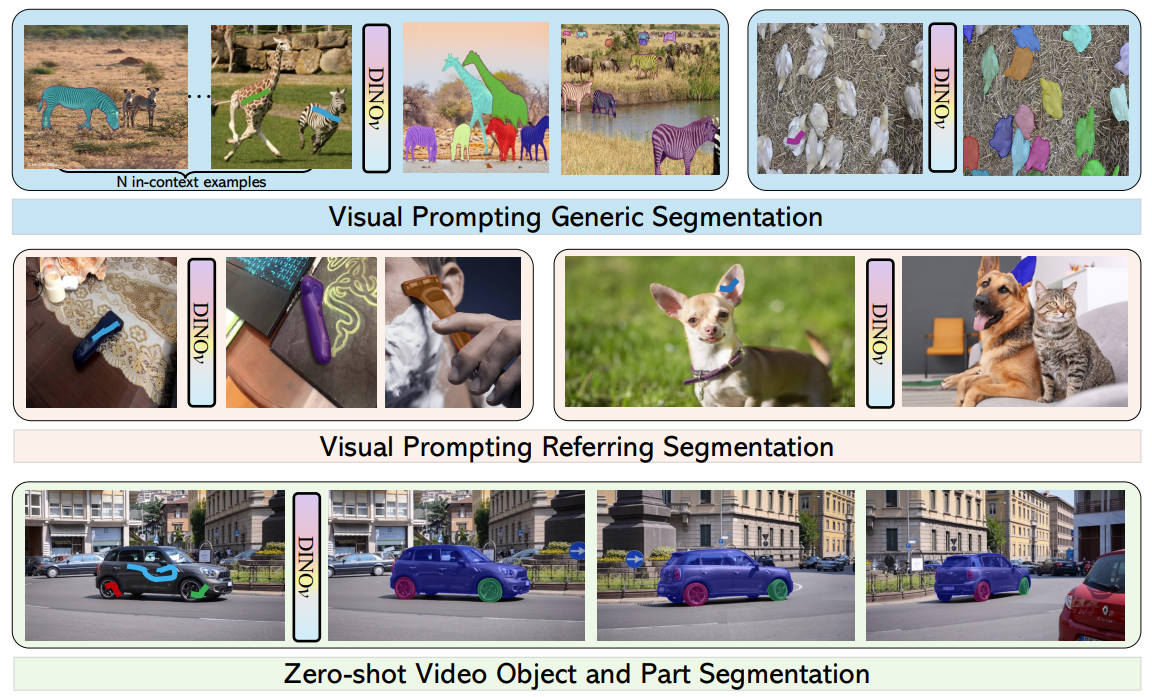
@inproceedings{li2024visual,
title = {Visual In-Context Prompting},
author = {Li, Feng and Jiang, Qing and Zhang, Hao and Liu, Shilong and Xu, Huaizhe and Zou, Xueyan and Ren, Tianhe and Li, Hongyang and Zhang, Lei and Li, Chunyuan and Yang, Jianwei and Gao, Jianfeng},
booktitle = {Computer Vision and Pattern Recognition (CVPR)},
year = {2024}
}

@inproceedings{huang2024tag,
title = {Tag2Text: Guiding Vision-Language Model via Image Tagging},
author = {Huang, Xinyu and Zhang, Youcai and Ma, Jinyu and Tian, Weiwei and Feng, Rui and Zhang, Yuejie and Li, Yaqian and Guo, Yandong and Zhang, Lei},
booktitle = {International Conference on Learning Representations (ICLR)},
year = {2024}
}
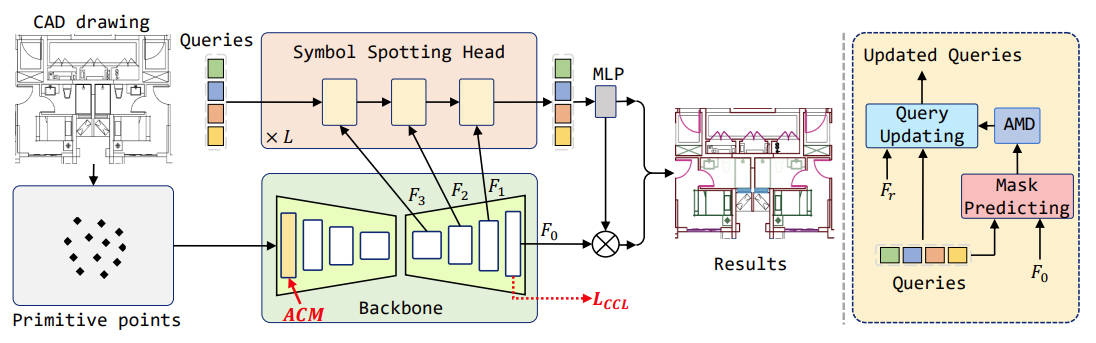
@inproceedings{liu2024symbol,
title = {Symbol as Points: Panoptic Symbol Spotting via Point-based Representation},
author = {Liu, Wenlong and Yang, Tianyu and Wang, Yuhan and Yu, Qizhi and Zhang, Lei},
booktitle = {International Conference on Learning Representations (ICLR)},
year = {2024}
}
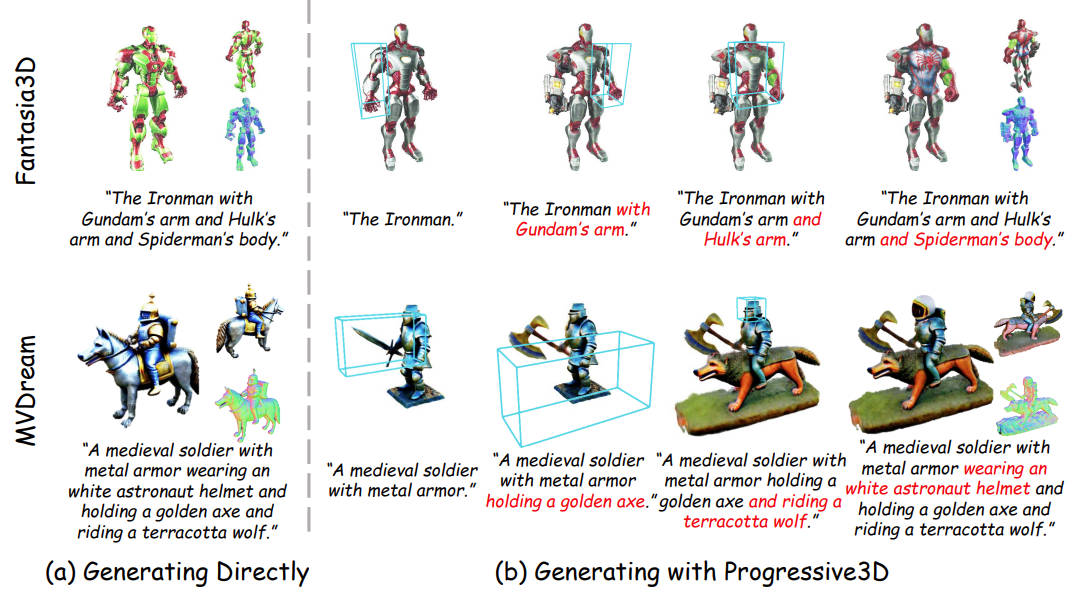
@inproceedings{cheng2024progressive,
title = {Progressive3D: Progressively Local Editing for Text-to-3D Content Creation with Complex Semantic Prompts},
author = {Cheng, Xinhua and Yang, Tianyu and Wang, Jianan and Li, Yu and Zhang, Lei and Zhang, Jian and Yuan, Li},
booktitle = {International Conference on Learning Representations (ICLR)},
year = {2024}
}
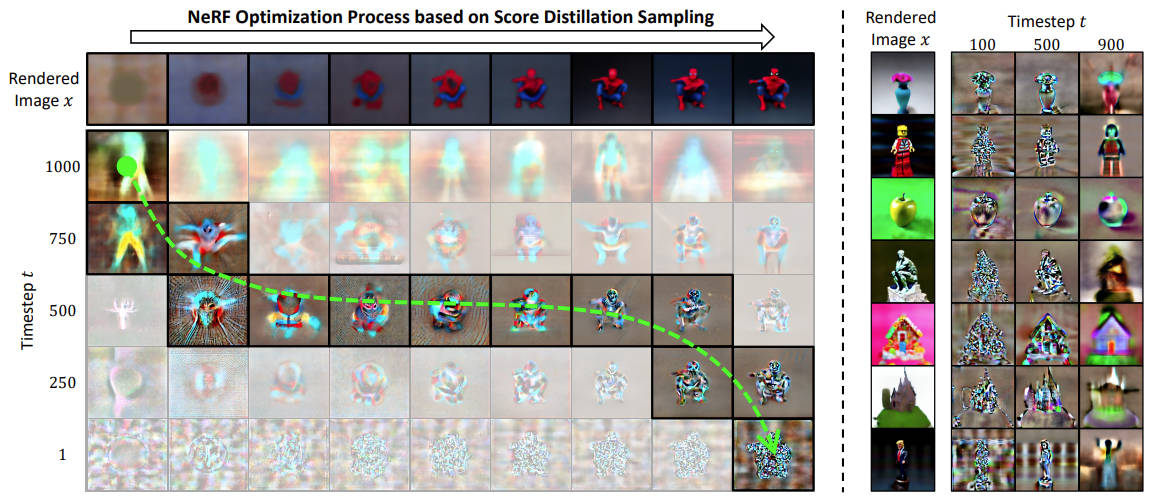
@inproceedings{huang2024dreamtime,
title = {DreamTime: An Improved Optimization Strategy for Diffusion-Guided 3D Generation},
author = {Huang, Yukun and Wang, Jianan and Shi, Yukai and Tang, Boshi and Qi, Xianbiao and Zhang, Lei},
booktitle = {International Conference on Learning Representations (ICLR)},
year = {2024}
}

@inproceedings{shi2024toss,
title = {TOSS: High-quality Text-guided Novel View Synthesis from a Single Image},
author = {Shi, Yukai and Wang, Jianan and CAO, He and Tang, Boshi and Qi, Xianbiao and Yang, Tianyu and Huang, Yukun and Liu, Shilong and Zhang, Lei and Shum, Heung-Yeung},
booktitle = {International Conference on Learning Representations (ICLR)},
year = {2024}
}

@inproceedings{huang2023dreamwaltz,
title = {DreamWaltz: Make a Scene with Complex 3D Animatable Avatars},
author = {Huang, Yukun and Wang, Jianan and Zeng, Ailing and Cao, He and Qi, Xianbiao and Shi, Yukai and Zha, Zheng-Jun and Zhang, Lei},
booktitle = {Conference on Neural Information Processing Systems (NeurIPS)},
year = {2023}
}

@inproceedings{cai2023smplerx,
title = {SMPLer-X: Scaling Up Expressive Human Pose and Shape Estimation},
author = {Cai, Zhongang and Yin, Wanqi and Zeng, Ailing and Wei, Chen and Sun, Qingping and Wang, Yanjun and Pang, Hui En and Mei, Haiyi and Zhang, Mingyuan and Zhang, Lei and Loy, Chen Change and Yang, Lei and Liu, Ziwei},
booktitle = {Conference on Neural Information Processing Systems (NeurIPS)},
year = {2023}
}
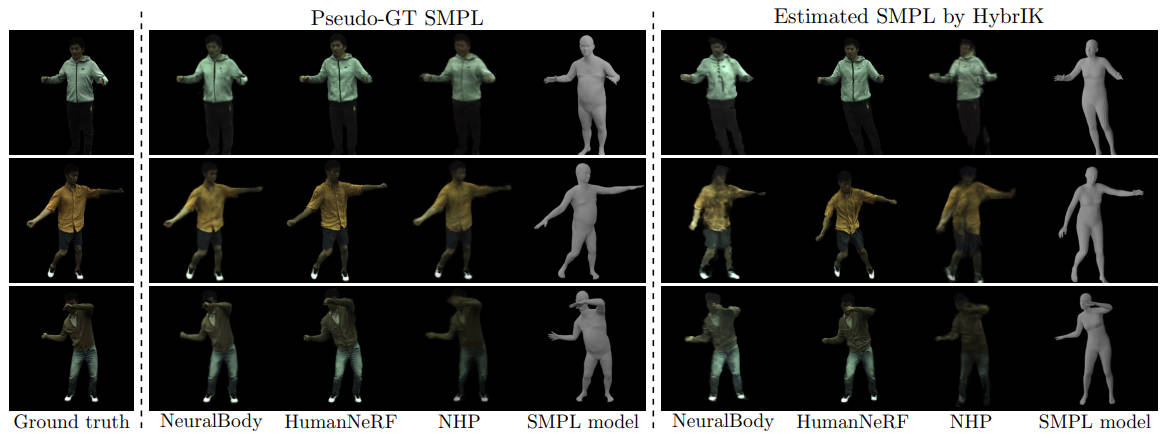
@inproceedings{liu2023comprehensive,
title = {A Comprehensive Benchmark for Neural Human Body Rendering},
author = {Liu, Kenkun and Jin, Derong and Zeng, Ailing and Han, Xiaoguang and Zhang, Lei},
booktitle = {Conference on Neural Information Processing Systems (NeurIPS)},
year = {2023}
}